Assessing the compressive strength (CST) of ground granulated blast furnace slag (GGBS) concrete is vital for ensuring structural safety and promoting sustainability in civil engineering. Traditional laboratory testing methods can be lengthy and cumbersome, prompting researchers to explore machine learning (ML) models for faster predictions. However, these models encounter significant challenges, such as inconsistent results stemming from unclear data proportionality, multicollinearity among input variables, and the absence of a standardized optimal model specifically for predicting GGBS concrete strength.
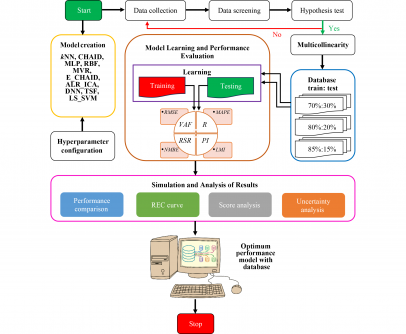
To address these issues, a collaborative research team from Rajasthan Technical University in India, the School of Pedagogical & Technological Education in Greece, and the National Institute of Technology Patna in India conducted a study titled “Data Proportionality and Its Impact on Machine Learning Predictions of Ground Granulated Blast Furnace Slag Concrete Strength.” The research investigated the performance of ten different ML models, including k-nearest neighbor (kNN), Chi-square Automatic Interaction Detection (CHAID), and Deep Neural Network (DNN), among others. The focus was on understanding the implications of data proportionality and multicollinearity on the predictions of concrete strength.
The study compiled a comprehensive database comprising 268 GGBS concrete specimens, with inputs including temperature, water-binder ratio, GGBS-binder ratio, water content, fine and coarse aggregate proportions, and superplasticizer use, while the output measured CST. The researchers tested three distinct data splits: 70% training to 30% testing, 80% to 20%, and 85% to 15%. They also performed a multicollinearity analysis using the Variance Inflation Factor (VIF) to evaluate the relationships among the input variables.
Findings revealed that the Takagi-Sugeno Fuzzy (TSF) model exhibited superior performance compared to the other models. With an 85% training split, TSF achieved a correlation coefficient (R) of 0.9780, a root mean square error (RMSE) of 3.2460 MPa, a prediction interval (PI) of 1.86, and a20-index of 93.75 during the testing phase. This marked a significant improvement over the Multilayer Perceptron (MLP) model, which achieved an R of 0.8389 with an 80% training split, and kNN.
The analysis also indicated that multicollinearity issues, specifically with the GGBS-binder ratio and fine aggregate, negatively impacted the performance of kNN and MLP. Furthermore, using 85% of the data for training reduced the risk of overfitting, as demonstrated by a decrease in overfitting for the TSF model from 2.18 to 1.38, enhancing its generalization capabilities.
This research, authored by Jitendra Khatti, Panagiotis G. Asteris, and Abidhan Bardhan (the corresponding author), signifies a crucial step toward refining the application of machine learning in predicting the strength of GGBS concrete. For further details, the full text is available at this link.


