In the realm of geotechnical engineering, the overconsolidation ratio (OCR) plays a crucial role in understanding soil stress history, which in turn affects soil stability and deformation characteristics. Traditional methods for measuring OCR through laboratory consolidation tests are often cumbersome and costly. Furthermore, existing analytical and empirical methods reliant on piezocone penetration test (CPTU) data have shown limited effectiveness due to the complex nonlinear relationships between CPTU parameters and OCR. This gap highlights the necessity for improved methods to accurately and efficiently predict OCR across various clay conditions.
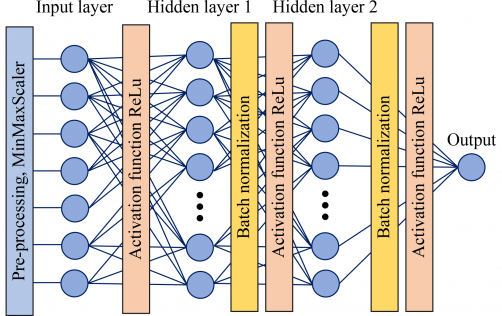
A research collaboration involving Western Sydney University in Australia, the Alfred-Wegener-Institut Helmholtz Center for Polar and Marine Research in Germany, University of Bremen in Germany, and Gdansk University of Technology in Poland has initiated a study titled “Comparative study on data-driven prediction of overconsolidation ratio using supervised machine learning models.” This investigation introduces five supervised machine learning models—gradient boosting machine (GBM), random forest (RF), artificial neural network (ANN), support vector machine (SVM), and eXtreme gradient boosting (XGB)—to forecast clay OCR based on CPTU data.
The team employed the “GridSearchCV” function from the Scikit-learn package for hyperparameter tuning and k-fold cross-validation, aiming to enhance model performance. The models utilized input features such as vertical total stress (σv0), hydrostatic pore water pressure (u0), corrected cone resistance (qt), and pore pressures at the cone tip (u1) and above the cone base (u2), as well as clay type (intact or fissured). A preliminary analysis indicated that incorporating double-element CPTU data (u1 + u2) significantly improved prediction accuracy.
The study analyzed 488 valid records, allocating 75% for training and 25% for testing the models. Sensitivity analysis revealed that the corrected cone resistance (qt) was the most impactful feature for RF, GBM, XGB, and SVM models, while the ANN was influenced by all input variables. The findings demonstrated that the XGB model achieved the highest performance metrics (test set R² = 0.94, MAE = 0.92, RMSE = 2.51), followed closely by RF (R² = 0.93), GBM (R² = 0.92), and ANN (R² = 0.90), all exceeding R² values of 0.90. The SVM model, however, had the lowest performance (R² = 0.83).
Moreover, the machine learning models exhibited a significant advantage over traditional empirical relationships. The research paper, “Comparative study on data-driven prediction of overconsolidation ratio using supervised machine learning models,” is co-authored by Mohsen Misaghian, Faramarz Bagherzadeh, and Lech Bałachowski, with Misaghian serving as the corresponding author (E-mail: [email protected]).
For further details, the full text of the open access paper can be accessed at this link.